
Week 5 – Problem Management
September 23, 2025
After spending the last week exploring the Service Desk, this week my focus shifted to Problem Management. If Incident Management is about putting out fires quickly, Problem Management is about asking why the fire started in the first place and making sure it never happens again.
By the end of the week, I could clearly see how Problem Management differs from Incident Management. Incidents are about restoring service immediately, while Problems are about digging into the root cause, preventing repetition, and reducing long-term risk. ITIL 4 taught me that Problem Management is structured around three big activities: Problem Identification, Problem Control, and Error Control.
Understanding Problem Management
The first task asked me to define Problem Management in my own words. I described it as a structured practice focused on identifying, analyzing, and eliminating the root causes of incidents.
As I wrote, I realized its value lies in being proactive. Users often only care if the service comes back. But behind the scenes, IT must care about preventing the same disruption tomorrow. That’s where Problem Management begins.
At first, I thought this was just another layer of Incident Management. But as I reflected, I saw the contrast:
Problems are about prevention, understand and eliminate the cause.
Incidents are about speed, restore the service quickly.
The Lifecycle of a Problem
When I reached this part of the assignment, I realized Problem Management is not just one big activity, it is a set of sub-processes, each with its own role in preventing recurring incidents. Writing them out made me feel like I was mapping the different gears in a machine: every piece turns to keep the system running smoothly.
| Sub-Process | Purpose |
|---|---|
| Proactive Problem Identification | Increase service availability by proactively identifying Problems—finding issues before incidents recur. |
| Problem Categorization and Prioritization | Record and prioritize Problems accurately to ensure quick and effective resolution. |
| Problem Diagnosis and Resolution | Identify the root cause of a Problem and initiate the most suitable and efficient solution. Provide a temporary workaround if possible. |
| Problem and Error Control | Monitor unresolved Problems and their processing status to enable corrective action if needed. |
| Problem Closure and Evaluation | After a permanent solution is applied, ensure the Problem Record contains a complete historical description and update Known Error Records as needed. |
| Major Problem Review | Conduct a formal review of major Problem resolutions to ensure the issue is fully addressed and generate lessons learned to prevent recurrence. |
| Problem Management Reporting | Provide Problem reports, including status, available workarounds, and a list of outstanding problems to other service management processes and IT management. |
Measuring Success with KPIs
The next task made me think about how we measure success. With incidents, the KPI is usually speed, how fast did you respond, how fast did you close the ticket?
But with Problem Management, the story is different. It’s measured by how many problems were eliminated, how many root causes were identified, and whether repeat incidents declined. Even customer satisfaction became an important measure, because if problems are solved permanently, users begin to notice stability and reliability.
| KPI | Description |
|---|---|
| Number of problems recorded | Measures the number of problems identified in a given period. |
| Average resolution time | Average time taken to resolve problems. |
| % of problems with identified root cause | Percentage of problems where the root cause was successfully identified. |
| % of problems resolved with workaround | Percentage of problems temporarily addressed with a workaround. |
| Number of repeat incidents | Measures the effectiveness of problem management in preventing recurring incidents. |
| Customer satisfaction | Level of user satisfaction regarding problem resolution. |
To me, these KPIs told a bigger story: success here is not about racing to the finish line, but about making sure the race track itself is safe for the future.
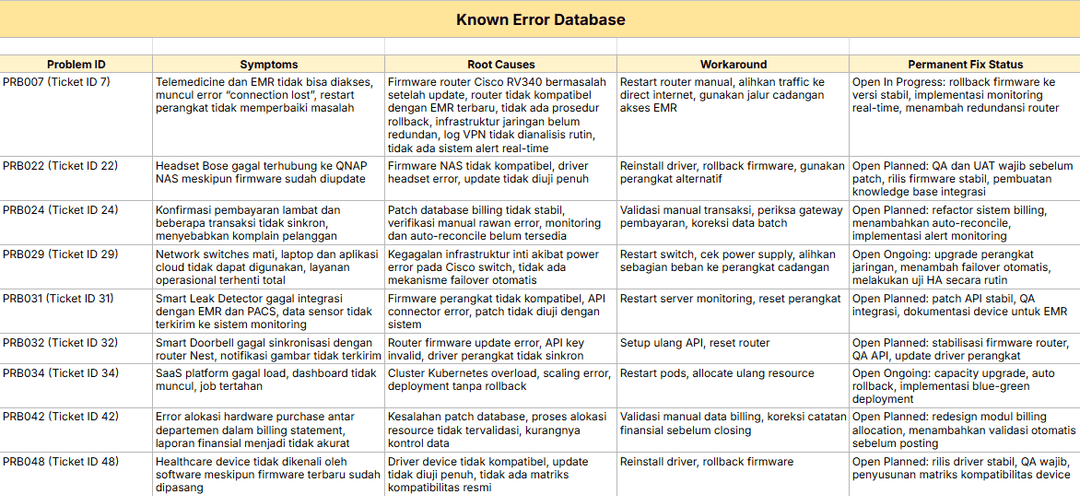
Known Error Database (KEDB)
This was my “aha” moment of the week. The KEDB is like a memory bank for IT. It stores every known problem and its workaround so that the next time it appears, no one has to start from scratch.
The KEDB was one of the most fascinating discoveries this week. It works like the organization’s memory bank, a repository where every identified problem, its root cause, and its workaround are stored. Instead of starting from scratch every time a repeated incident occurs, Service Desk agents can check the KEDB and instantly apply a solution.
For example, we discussed a case where a bug in an HR application caused login failures when users opened it on older browsers. The root cause had already been identified, and the workaround was simple: advise users to switch to the latest browser version. Once this information was recorded in the KEDB, the Service Desk could respond in seconds instead of wasting time reanalyzing the same bug.
This is a KEDB that I created on the Lab Session
Workarounds as Survival Tools
One of the most important lessons I picked up this week was the role of workarounds. At first, I thought of them as “half-baked fixes,” something you do when you can’t solve the problem properly. But the more I studied, the more I realized that workarounds are actually survival tools. They buy time, reduce impact, and keep users productive while IT works on a permanent solution.
Take the example of the HR application bug that caused login failures on outdated browsers. The permanent fix required patching the application, which would take time. But the workaround, advising users to update to the latest browser, gave employees immediate access to the system. It didn’t remove the bug, but it restored productivity almost instantly.
In my group’s lab exercise, I saw this play out again with the VPN router connectivity problem. The root causes included firmware incompatibility and lack of redundancy. A permanent solution meant rolling back firmware versions and redesigning the network. But in the meantime, the workaround was to manually restart the router and redirect traffic through alternative access points. It wasn’t elegant, but it kept critical healthcare services like Telemedicine and EMR online.
These stories helped me see that workarounds are not failures, they are acts of resilience. They prove that in ITSM, success is not always about perfection, but about flexibility and pragmatism. A good workaround can make the difference between an organization grinding to a halt and one that keeps moving while engineers quietly prepare the permanent cure.
The Link Between Incident and Problem Management
| Aspect | Incident Management | Problem Management | Relationship |
|---|---|---|---|
| Focus | Restoring services as quickly as possible. | Finding the root cause of incidents to prevent recurrence. | Frequent incidents can trigger problem management analysis. Results from problem management (such as workarounds or KEDB) are used by incident management to speed up service restoration. |
| Role | Process for restoring service fast. | Process for eliminating causes and preventing future incidents. |